
Context
I’m the CTO of Jobboard startup and one of the main developers of the project. As time goes, I added more features to the platform and I decided a few years back to create a “similar jobs” function. That function would be pretty easy, I take an id of a job as input, a radius and a limit and I return a set of ids of other jobs. After 2 years the number of jobs was multiplied by 4 and the function which was fast at the beginning (avg. 250ms per query) started to get slowly but also inconsistently slowly (some queries took 300 ms and some others 10 seconds).
Here is the original query:
Postponing the problem
As a lazy developer I thought that this degraded performance was “normal” as more jobs -> more similar jobs-> slower queries. Moreover, it was not as urgent as some other problems that we had at that time.
To fix this issue, I noticed that this query first ran directly on the HTML rendering side (we use Jinja), the easy fix was to return the HTML part quickly (without the similar jobs) and then make a XHR request (via an API endpoint) to load the similar jobs once the DOM is loaded. Easy fix, 5 lines and then I forgot about it.
The crash
As load increased steadily, I had some alerts sometimes but nothing really problematic so I ignored that to focus on some bigger problems we had (a startup has a lot of problems). Until a sunday night where the production servers were under heavy googlebot load and the query for the similar jobs were bloating the query queue.
So I played the firefighter and removed the calls to the similar jobs function for the moment in order to get back to an acceptable performance.
Fixing the issue
At that moment in time, it was clear that there will be no other solution than rewriting the query which was now inadequate to the environment. However, I had no clue how.
So, I made the same as in “Who Wants to be a Millionaire” and I called a friend: Matthieu. Matthieu has a deep understanding of databases (he worked on database engines).
We first test the query in a local environment and find nothing big, the query does few joins but with less than 30K jobs offers, every query returns in less than 500ms. So we need to test the queries in production…
After some EXPLAIN ANALYSE we consider that the join of a few tables like location_tb, b2b_tb and some filtering could be done upfront and would require a materialized view.
Materialized view
Materialized views are great in postgres, they allow you to generate static tables based on a query. In our case we selected all the jobs which could be a similar job and packed them inside a new materialized view (basically, you do not want to recommend a job which is already finished or a job where you do not earn any money, so we can eliminate ~80% of our job_tb — we store every posted job 6 months after deletion to run some analysis afterwards).
That way we save the join time that the legacy query needed to gather all the data together.
There is a pretty important thing to think about when you create a materialized view (at least in my case if you have a decent load on the server): add a UNIQUE INDEX. It will allow you to use the REFRESH MATERIALIZED VIEW CONCURRENTLY feature which, as stated in the docs: refreshes the materialized view without locking out concurrent selects on the materialized view. Meaning that my job, b2b or location table can still be used while refreshing the view. However the docs also stated that: this option is only allowed if there is at least one UNIQUE index on the materialized view which uses only column names and includes all rows.
In our case I just put an index on the id column of the materialized view.
The materialized view and its index:
ST_DWithin
If you have a look at the original query, you see that we use the ST_DISTANCE function to filter and order the results. However, we found that this method cannot use any index (thanks to this article):
ST_DWithincan use an index andST_Distancecan not
We needed then to add an index on the location column of our materialized view:
CREATE INDEX similar_mv_loc ON similar_mv USING GIST (location)
We just followed the example in the manual that you can find here.


The new query
Now that we have a materialized view and another approach for the query (with st_dwithin), we need to update the query:
Conclusion
We have some shiny performances now!

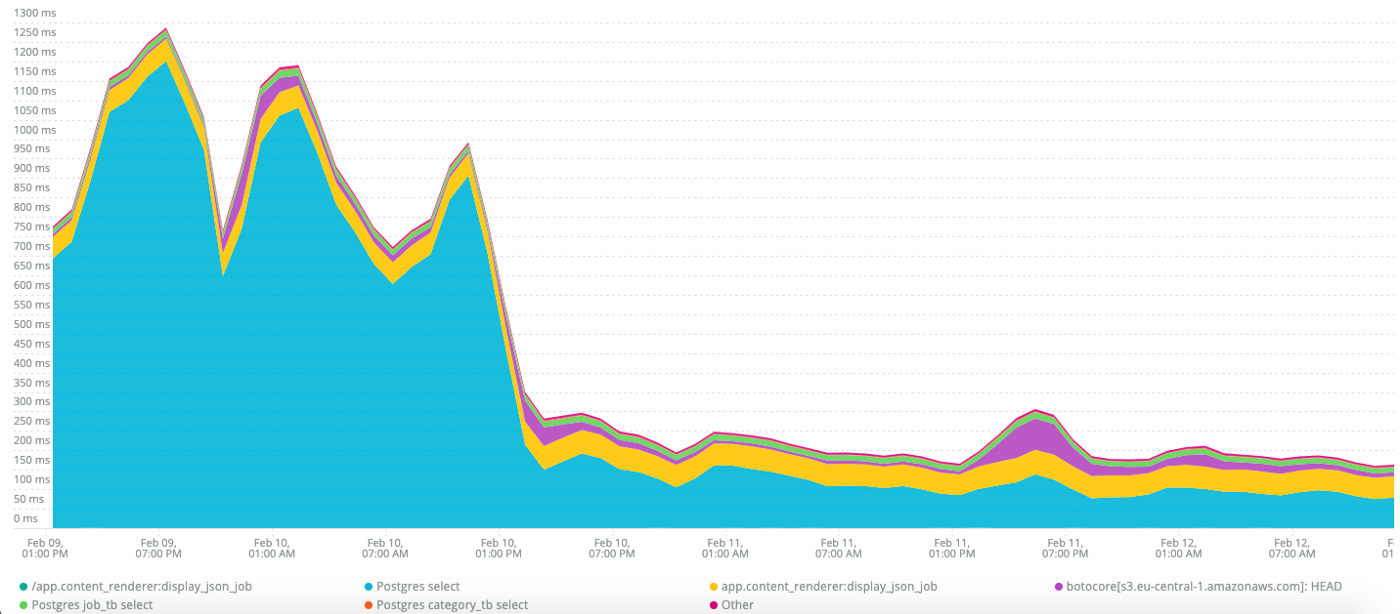
While it was stressful at the beginning (note to myself, never postpone problems again!), this issue was interesting because I could gather more insights about geo queries. Also I now consider materialized view as an easy and understandable way to dramatically improve the performance of your app without having to scale up the infrastructure.